



目次
記事説明
この記事では、「Management & Governance」分野の重要なサービスである、
Amazon CloudWatchについて説明します。
↓Management & Governanceの重要なサービス一覧
・Amazon CloudWatch
・AWS CloudFormation
・AWS CloudTrail
・AWS Config
・AWS Systems Manager
↓参考:【AWS Black Belt Online Seminar】Amazon CloudWatch
https://d1.awsstatic.com/webinars/jp/pdf/services/20190326_AWS-BlackBelt_CloudWatch.pdf
Amazon CloudWatchの位置づけ
Amazon Management Toolsとして、5つの機能が提供されています。
1.リソースプロビジョニング
⇒テンプレート定義によるインフラプロビジョニングの自動化
主なサービス:AWS CloudFormationなど
2.構成管理
⇒パッケージの導入、ソフトウェアとリソースのコンフィグレーション、パッチ適用
主なサービス:AWS Systems Managerなど
3.モニタリング
⇒AWSリソースやアプリケーションに対する、モニタリング、アラーム、
メトリクスダッシュボード、ログ、イベント管理
主なサービス:Amazon CloudWatch
4.ガバナンスとコンプライアンス
⇒リソースインベントリ、構成変更管理、ユーザ操作とAPI呼び出しの記録、
セルフマネージドなITカタログ
主なサービス:AWS CloudTrail、AWS Config
5.リソース最適化
⇒コスト低減、パフォーマンス向上、セキュリティの改善に対する推奨事項の自動提供
主なサービス:AWS Trusted Advisor
このうち、Amazon CloudWatchは
Amazon Management Toolsの中のモニタリング機能として用いられます。
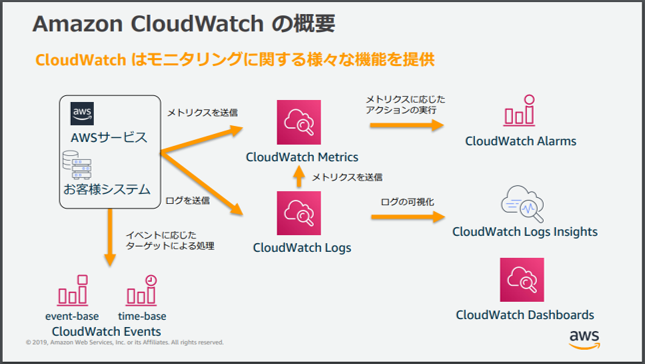
Amazon CloudWatchの概要
概要としては、
「AWSサービスや、システムのモニタリングに関する様々な機能を提供する」
サービスで、AWSサービスだけでなく、社内のオンプレサーバや他のクラウドサーバでの監視も可能です。
CloudWatchの重要な要素として、5つ挙げられます。
1.CloudWatch Metrics
⇒CloudWatchに発行されたメトリクス(測定データ)を収集し、統計を取得します。
2.CloudWatch Alarms
⇒CloudWatch Metricsをモニタリングして、アラームを発行可能で、
条件を指定して自動アクション(通知や復旧など)を実行可能です。
3.CloudWatch Logs
⇒AWSサービスもしくはシステムのログ監視、保存、アクセスを提供します。
4.CloudWatch Dashboards
⇒CloudWatch コンソールでカスタマイズ可能なダッシュボードを作成できます。
5.CloudWatch Events
⇒リソース変更のイベントやスケジュールをトリガーとして、アクションを実行できます。
 ↓引用元
↓引用元
https://d1.awsstatic.com/webinars/jp/pdf/services/20190326_AWS-BlackBelt_CloudWatch.pdf
それでは順に説明していきます。
CloudWatch Metricsについて
CPU使用率や5XX errorなど、様々な測定データのことを、AWSではメトリクスと呼びます。
時系列のデータポイントとして、タイムスタンプと測定単位を保持します。
例)08:00にCPU使用率:85% 等
様々なメトリクスの収集、統計結果を管理するのがCloudWatch Metricsとなります。
メトリクスデータの生成
• 基本は1分、カスタムメトリクスの高解像度を利用して最短で1秒間隔で生成されます。
• EC2では基本モニタリングで5分、詳細モニタリングで1分ごとにメトリクスが生成されます。
メトリクスデータの利用可能期間
• 粒度によって利用可能期間が決まります。
• 1分未満 ⇒ 3時間、1分 ⇒ 15日、5分 ⇒ 63日
• 1時間のデータポイントだと15ヶ月(1年前のイベントとの比較に使えます)
| 高解像度 | 標準の解像度 | |||
| 取得粒度 | 1分未満 | 1分~ | 5分~ | 1時間~ |
| 利用可能期間 | 3時間 | 15分 | 63日 | 15か月 |
メトリクス値としては下記のようなデータが収集されます。
・Minimum : 指定された期間に認められた最小値
・Maximum :指定された期間に認められた最大値
・Sum : メトリクスで加算されたすべての合計値
・Average : 指定した期間の平均値(Sum/SampleCount)
・SampleCount : データポイントのカウント数
・pNN,NN : 指定されたパーセンタイルの値(パーセント値)
↓その他の機能
Metric Mathについて、
標準メトリクスでは欲しいデータを収集できない場合、
CloudWatchメトリクスに数式を使用して、新しいメトリクスを作成できます。
スナップショットグラフについて、
CloudWatchコンソールでメトリクスを表示した際のグラフをPNG画像として取得できます。
異常検知の際にグラフを添付したい際などに有用です(CloudWatch Alarmsと組み合わせ)
EC2で標準メトリクスとされるもの
• CPUUtilization(CPU使用率)
• CPUCreditBalance(獲得CPUクレジット数)
• CPUCreditUsage(CPUクレジットの使用)
• CPUSurplusCreditBalance(獲得CPUクレジットが消費された後の、余剰CPUクレジット数)
• CPUSurplusCreditsCharged(課金が発生する余剰CPUクレジット数)
• DiskReadBytes(ディスク読み取りバイト数)
• DiskReadOps(読み取り操作回数)
• DiskWriteBytes(ディスク書き込みバイト数)
• DiskWriteOps(書き込み操作回数)
• NetworkOut(送信ネットワークトラフィックのバイト数)
• NetworkPacketsOut(送信パケット数)
• NetworkIn(受信ネットワークトラフィックのバイト数)
• NetworkPacketsIn(受信パケット数)
• StatusCheckFailed_Instance(インスタンスステータスチェック 0:成功、1:失敗)
• StatusCheckFailed_System(システムステータスチェック 0:成功、1:失敗)
• StatusCheckFailed(インスタンスとシステム両方のステータスチェック 0:成功、1:失敗)
その他のメトリクスについては、カスタムメトリクスとなり、
AWS CLIの”put-metric-data”もしくは”PutMetricData” APIでデータを登録し、
監視することができます。(解像度が 1秒のデータを含む高解像度なメトリクスを発行可能)
CloudWatch で利用できるエージェント/プロトコルについて
統合CloudWatch エージェント(推奨)
• メトリクスとログの両方を単一のエージェントで収集
• クラウドでもオンプレミスでも利用可能
• Linux, Windowsの両方で稼働。手動もしくはウィザードから設定が可能。
他にも、より詳しいメトリクスを収集する場合は、下記の方法があります。
StatsD のサポート
• StatsD プロトコルを使用して、カスタムメトリクスを取得(Linux,Windows)
collectd のサポート
• collectd プロトコルを使用してカスタムメトリクスを取得(Linux)
• collectd ソフトウェアを使用してCloudWatch エージェントにメトリクスを送信
procstatプラグイン
• 個別のプロセスからメトリクスを収集
• CloudWatchエージェントで設定
CloudWatch Alarmsについて
CloudWatch Alarmsは、CloudWatch Metricsをモニタリングして、アラームを発行可能で、
条件を指定して自動アクション(通知や復旧など)を実行する機能です。
例)CPU使用率が85%以上になった際、指定されたアドレスにアラートメールを送信する
アラームの状態としては3種類あります。
1.OK
⇒定義された閾値を下回っている状態です。問題ありません。
2.ALARM
⇒定義された閾値を上回っている状態です。発報されるべき状態です。
3.INSUFFICIENT_DATA
データ不足の為、状態を判定できない状態です。
必ずしも障害を表すステータスではなく、発報されるべきか判断できません。
また、データが欠落しているときの処理として、下記の設定が可能です。
| オプション | 設定内容 |
| missing | 不明ステータスとなる。デフォルト設定。 |
| notBreaching | 欠落データポイントは閾値内として判定される。 |
| breaching | 欠落データポイントは閾値超過として判定される。 |
| ignore | 現在のアラーム状態が維持される。 |
例)breachingのユースケース
EC2上の継続的にCPU使用率を監視しているようなシステムについて、
データポイントの欠落は異常として検知する。
例)notBreachingのユースケース
DynamoDBのスロットリングを監視しているシステムについて、
データポイントは正常時に生成されないので、閾値内とする。
その他にも、アラームを発生させるデータポイント数を設定可能です。
例)1分間隔のデータポイントが3回連続で異常だった場合、アラームを生成
CloudWatch Alarmsのアクション機能について
異常(アラーム)が検知された際の挙動を設定することができます。
異常を検知するタイミングが深夜だった場合、人の手で復旧作業せずに
自動で復旧してくれると嬉しいですよね。
例)EC2インスタンスの自動復旧
CloudWatch:StatusCheckFailed_Systemのアラームをキャッチ
↓
CloudWatch Alarms(アクション):SNSトピックを作成、EC2インスタンスの再起動
↓
SNS:Eメールで指定アドレスへ通知
CloudWatch Logsについて
AWSサービスおよびシステムのログ監視をする機能です。
エージェント経由でログをCloudWatchエンドポイントへ送信します。
※S3へのエクスポートも可能
CloudWatch Logsのディレクトリ階層については、下記のようになります。
ロググループ > ログストリーム > ログイベント
例)社内に3つのwebサーバがあった場合
ロググループ:webサーバ
ログストリーム:Aサーバ、Bサーバ、Cサーバ
ログイベント:それぞれのサーバでの、イベント発生時のタイムスタンプ+メッセージ
※この場合の数的関係性は、ロググループ:ログストリーム:ログイベント=1:3:多
収集したログについて
・ログの内容はタイムスタンプとログメッセージ(UTF-8)で構成される
・ログの保存期間は、永久保存が可能
・Amazon S3へのエクスポートが可能
・特定文字列でフィルタリング検索が可能(正規表現利用不可)
・特定文字列のエントリ頻度でアラームを作成、SNS連携が可能
・収集したログをフィルタパターンに応じて、下記のサービスに転送可能(AWS CLIからのみ)
⇒Kinesis Data Streams
⇒Kinesis Data Firehose
⇒Lambda
その他、CloudWatch Logs Insightsという、CloudWatch Logsのログデータを
専用のクエリ言語で検索して分析できる機能があり、グラフで可視化することも可能です。
CloudWatch Dashboardsについて
CloudWatch コンソールでカスタマイズ可能なダッシュボードを作成できます。
自分の監視したいメトリクスを指定して、一度に閲覧することができます。
これは、CloudWatch Alarmsと統合することで、
Alarm状態になるとウィジェットが赤に変わるため、
一目見て異常が起こっているかを監視することができます。
CloudWatch Eventsについて
リソース変更のイベントやスケジュールをトリガーとして、アクションを実行する機能です。
トリガーとなる要素は大きく分けて、2種類存在します。
1.event-base
リソースの変更を行うシステムイベントを処理させることができます。
例)EC2のRunningイベントをキャッチして、指定タグが付いていない場合は、終了する。
2.time-base
ターゲットに対して、スケジューリングを行ってイベントを処理させることが可能。
例)22:00になったら、EC2インスタンスの自動停止を行う。
まとめ
AWSのサービスの中で非常に重要な位置づけである、CloudWatchに関する記事でした。
CloudWatch Alarmsのアクション機能など、うまく活用することができれば、
運用コストを下げることができそうですね。
また、既に会社で別の監視ツールを活用しているという方もいらっしゃると思います。
現に前職では、異常があればすぐに担当者へ電話をかけてもらうような24時間365日対応の監視サービスを利用しておりました。
CloudWatchではEメールでの通知となるので、
電話ですぐに連絡してもらいたい場合などは、別のサービスを用いる方が良いかもしれません。
なので、下記のような使い分けをすれば良いと思います。
障害検知後すぐに電話での連絡を要する ⇒ 別の監視サービスを利用
障害検知から自動的にAWSのサービスのイベントを実行 ⇒ CloudWatch利用
それでは、お読みいただきありがとうございました。